Blog sobre Inteligência Artificial, onde se discute temas e conceitos referentes à Inovação, tais como, IA, IA Generativa (GenAI), Fintechs, Blockchain e Internet das Coisas (IoT)
Vivemos uma revolução inconteste impulsionada pela Inteligência Artificial (IA) dentro e fora das empresas. Mas será que o aprendizado de máquina ainda é relevante no mundo corporativo?
Nos últimos tempos, a IA tem sido um dos tópicos mais discutidos no mundo corporativo. A IA Gerenativa (GenAI), em particular, tem atraído grande interesse, com empresas de todos os setores explorando seu potencial para criar novos produtos e serviços.
Apesar do hype em torno da GenAI, a IA Preditiva (PredAI), baseada no Aprendizado de Máquina (Machine Learning - ML), ainda é uma tecnologia importante para as empresas. O ML é uma sub-área da IA que usa algoritmos para aprender a partir de dados. Essa capacidade de aprender a partir de dados é essencial para uma ampla gama de aplicações corporativas, incluindo:
Recomendação de produtos: O ML é usado para recomendar produtos aos clientes com base em seu histórico de compras e interesses.
Análise de fraude: O ML é usado para identificar fraudes financeiras.
Diagnóstico médico: O ML é usado para ajudar os médicos a diagnosticar doenças.
Previsão de demanda: O ML é usado para prever a demanda por produtos ou serviços.
A IA Gerenativa e o Aprendizado de Máquina são dois subconjuntos da Inteligência Artificial (IA). A principal diferença entre eles é que a IA Gerenativa é usada para criar novos dados, enquanto o Aprendizado de Máquina é usado para aprender a partir de dados existentes.
O ML é uma tecnologia madura e já é usada em uma ampla gama de aplicações corporativas. É uma tecnologia relativamente acessível e pode ser facilmente personalizada para atender às necessidades específicas de uma empresa.
A IA Gerenativa usa algoritmos para criar novos dados que são semelhantes aos dados que já existem. Por exemplo, a IA Gerenativa pode ser usada para criar novas imagens, textos ou músicas que são semelhantes a imagens, textos ou músicas existentes.
O Aprendizado de Máquina usa algoritmos para aprender a partir de dados existentes. Por exemplo, o Aprendizado de Máquina pode ser usado para treinar um modelo que possa prever se um cliente vai cancelar sua assinatura ou se um paciente vai ter um ataque cardíaco.
Aqui está uma tabela que resume as principais diferenças entre a IA Gerenativa e o Aprendizado de Máquina:
IA Preditiva (Machine Learning)
Usada para fazer previsões ou classificações com base em dados de entrada
Treinado usando dados históricos e depois aplicado a novos dados
Os dados de treinamento são únicos e específicos para tarefa à qual o modelo será usado
Tipos de dados necessários: dados rotulados com pares de entrada-saída, em que a saída é o rótulo ou valor de destino
Generative AI (Large Language Models)
Cria novos dados com base nos padrões que aprendeu com os dados de treinamento
Pode ser usada para tarefas como geração de imagem ou texto, em que o modelo cria novas imagens ou textos semelhantes aos dados de treinamento
Os dados de treinamento são gerais e não específicos (para uma tarefa em particular), o modelo é capaz de gerar dados novos e exclusivos que nunca foram vistos antes
Tipos de dados necessários: dados não rotulados, tais como imagens, texto ou áudio, que o modelo usa para aprender padrões e recursos
O pré-treinamento é comumente usado para aprender recursos gerais de um grande conjunto de dados, antes de fazer o ajuste fino em um conjunto de dados específico menor
A IA Gerenativa e o Aprendizado de Máquina são duas tecnologias poderosas que estão sendo usadas em uma ampla gama de aplicações. A IA Gerenativa é particularmente promissora para aplicações que exigem a criação de novos dados, como geração de conteúdo criativo ou tradução automática. O Aprendizado de Máquina é particularmente promissor para aplicações que exigem a análise de dados existentes, como diagnóstico médico ou recomendação de produtos.
Embora a GenAI seja uma tecnologia promissora, o ML ainda é uma tecnologia importante para as empresas. O ML é uma tecnologia madura e já é usada em uma ampla gama de aplicações corporativas. É uma tecnologia relativamente acessível e pode ser facilmente personalizada para atender às necessidades específicas de uma empresa.
Resumindo:
A IA Generativa se concentra na criação de conteúdo novo e original.
A IA Preditiva visa fazer previsões ou previsões precisas sobre eventos futuros.
Ambas são muito poderosas e possuem inúmeras aplicações.
A IA Generativa tem recebido muita atenção devido ao grande apelo e interatividade gerados por seus resultados para o consumidor final: ou seja, textos escritas, conteúdo de vídeo, sons de áudio e imagens geradas automaticamente do zero.
A IA Preditiva tende a ter mais aplicações nos bastidores para empresas que buscam executar operações de maneira mais eficiente e eficaz.
Finalmente, a IA está proliferando em um ritmo surpreendente, e esses dois tipos de IA atualmente lideram o grupo em casos de uso de alto valor agregado.
Este livro fornece uma ampla introdução aos algoritmos para tomada de decisão sob situações de incerteza, ao cobrir uma ampla variedade de tópicos relacionados à tomada de decisões.
Assim, são apresentadas formulações de problemas matemáticos subjacentes e os algoritmos para resolvê-los.
O livro adota uma abordagem baseada em agentes, ou entidades que agem com base em observações de seu ambiente. Agentes podem ser entidades físicas, como humanos ou robôs, ou podem ser entidades não físicas, como sistemas de suporte à decisão que são implementados inteiramente em software.
A interação entre o agente e o ambiente segue um ciclo ou loop "Observar - Agir", ou seja:
- O agente no tempo T recebe uma observação do ambiente; - As observações são frequentemente incompletas ou ruidosas;
- Com base nas entradas, o agente então escolhe uma ação por meio de algum processo de decisão;
- A ação escolhida, como o disparo de um alerta, pode ter um efeito não determinístico no ambiente;
- A narrativa enfoca agentes que interagem de forma inteligente para atingir seus objetivos ao longo do tempo; e
- Dada a sequência passada de observações e conhecimento sobre o ambiente, o agente deve escolher uma ação que melhor atinja seus objetivos na presença de várias fontes de incerteza, incluindo:
1. Incerteza do Resultado, onde os efeitos de nossas ações são incertos; 2. Incerteza do Modelo, onde nosso modelo do problema é incerto;
3. Incerteza de Estado, onde o verdadeiro estado do ambiente é incerto; e
4. Incerteza de Interação, onde o comportamento dos outros agentes que interagem no ambiente é incerto.
O livro está organizado em torno dessas quatro fontes de incerteza.
Finalmente, vale lembrar que tomar decisões na presença de incerteza é fundamental para o campo da inteligência artificial.
Grandes modelos de linguagem (Large Language Model - LLM) têm um desempenho muito ruim em tarefas que exigem planejamento metódico
Grandes modelos de linguagem (LLM) como o GPT-3 avançaram ao ponto de se tornar difícil medir os limites de suas capacidades. Quando se tem uma rede neural muito grande que pode gerar artigos, escrever código de software e se envolver em conversas sobre senciência e vida, deve-se esperar que ela seja capaz de raciocinar sobre tarefas e planejar como um humano faz, certo?
Errado! Um estudo realizado por pesquisadores da Arizona State University, em Tempe, mostra que, quando se trata de planejar e pensar metodicamente, os LLMs têm um desempenho muito ruim e apresentaam várias das falhas observadas nos atuais sistemas de aprendizado profundo.
Curiosamente, o estudo descobriu que, embora LLMs muito grandes como GPT-3, LaMDA e PaLM passem em muitos dos testes destinados a avaliar as capacidades de raciocínio e sistemas de inteligência artificial, eles o fazem porque esses benchmarks são muito simplistas ou simplesmente falhos e podem ser “enganados” por meio de truques estatísticos, cenário do qual os sistemas de aprendizado profundo são muito bons.
Com os LLMs abrindo novos caminhos todos os dias, os autores sugerem um novo benchmark para testar os recursos de planejamento e raciocínio dos sistemas de IA. Os pesquisadores esperam que suas descobertas possam ajudar a direcionar a pesquisa de IA para o desenvolvimento de sistemas de inteligência artificial que possam lidar com o que se tornou popularmente conhecido como tarefas de “System 2 Thinking”.
A ilusão de planejar e raciocinar
“No ano passado, estávamos avaliando a capacidade do GPT-3 de extrair planos de descrições de texto – uma tarefa que foi tentada com métodos de propósito especial anteriormente – e descobrimos que o GPT-3 de prateleira funciona muito bem em comparação com os métodos de propósito especial”, disse Subbarao Kambhampati, professor da Arizona State University e coautor do estudo, ao TechTalks. “Isso naturalmente nos fez pensar que ‘capacidades emergentes’ o GPT3 teria para resolver os problemas de planejamento mais simples (por exemplo, gerar planejamentos em brinquedos de estratégia). Descobrimos imediatamente que o GPT3 é espetacularmente ruim em testes anedóticos.”
No entanto, um fato interessante é que o GPT-3 e outros grandes modelos de linguagem têm um desempenho muito bom em benchmarks projetados para raciocínio de senso comum, raciocínio lógico e raciocínio ético, habilidades que antes eram consideradas fora dos limites para sistemas de aprendizado profundo. Um estudo anterior do grupo de Kambhampati na Arizona State University mostra a eficácia de grandes modelos de linguagem na geração de planejamentos a partir de descrições de texto. Outros estudos recentes incluem um que mostra que os LLMs podem fazer raciocínio de tiro zero (zero-shot reasoning) se fornecidos com uma frase-gatilho especial.
No entanto, o “raciocínio” é frequentemente usado amplamente nesses benchmarks e estudos, acredita Kambhampati. O que os LLMs estão fazendo, na verdade, é criar uma aparência de planejamento e raciocínio por meio do reconhecimento de padrões.
“A maioria dos benchmarks depende do tipo de raciocínio superficial (uma ou duas etapas), bem como tarefas para as quais às vezes não há verdade real (por exemplo, fazer com que os LLMs raciocinem sobre dilemas éticos)”, disse ele. “É possível que um mecanismo puramente de conclusão de padrões sem recursos de raciocínio ainda funcione bem em alguns desses benchmarks. Afinal, enquanto, algumas vezes, as habilidades do System 2 Reasoning podem ser compiladas para o System 1, em outras situações as ‘habilidades de raciocínio’ do System 1 podem ser apenas respostas reflexivas de padrões que o sistema percebeu em seus dados de treinamento, sem realmente realizar nada que se assemelhe ao raciocínio.”
System 1 e System 2 Thinking
Os sistemas de pensamento System 1 e o System 2 Thinking foram popularizados pelo psicólogo Daniel Kahneman em seu livro “Thinking Fast and Slow”. O primeiro (System 1) é o tipo de pensamento e ação rápido, reflexivo e automatizado que fazemos na maioria das vezes, como caminhar, escovar os dentes, amarrar os sapatos ou dirigir em uma área familiar. Mesmo uma grande parte da fala é realizada pelo System 1.
O System 2, por outro lado, é o modo de pensamento mais lento, que usamos para tarefas baseadas em planejamento e análise metódicos. Usamos o System 2 para resolver equações de cálculo, jogar xadrez, projetar software, planejar uma viagem, resolver um quebra-cabeça etc.
Porém, a linha entre o System 1 e o System 2 não é clara e evidente. Ao analisarmos a condução de um veículo, por exemplo, vemos como os sistemas podem se sobrepor. Quando estamos aprendendo a dirigir, devemos nos concentrar totalmente em como coordenar seus músculos para controlar a marcha, o volante e os pedais, ao mesmo tempo em que estamos de olho na estrada e nos espelhos laterais e traseiros. Este é claramente o System 2 em ação. Consome muita energia, requer toda nossa atenção e é lento. Mas à medida que repetimos os procedimentos gradualmente, aprendemos a fazê-los sem pensar. A tarefa de dirigir muda para o nosso System 1, permitindo que a executemos sem sobrecarregar a mente. Um dos critérios de uma tarefa que foi integrada ao System 1 é a capacidade de fazê-la inconscientemente enquanto se concentra em outra tarefa (por exemplo, podemos amarrar o sapato e falar ao mesmo tempo, escovar os dentes e ler, dirigir e conversar etc.).
Mesmo muitas das tarefas muito complicadas que permanecem no domínio do System 2 acabam se tornando parcialmente integradas ao System 1. Por exemplo, jogadores profissionais de xadrez confiam muito no reconhecimento de padrões para acelerar seu processo de tomada de decisão. Podemos ver exemplos semelhantes em matemática e programação, onde, depois de fazer as coisas repetidamente, algumas das tarefas que anteriormente exigiam um pensamento cuidadoso vêm a nós automaticamente.
Um fenômeno semelhante pode estar acontecendo em sistemas de aprendizado profundo que foram expostos a conjuntos de dados muito grandes. Eles podem ter aprendido a fazer a fase simples de reconhecimento de padrões de tarefas complexas de raciocínio.
“A geração de planos requer o encadeamento de etapas de raciocínio para chegar a um plano, e uma verdade firme sobre a correção pode ser estabelecida”, disse Kambhampati.
Um novo benchmark para planejamento de testes em LLMs
“Dada a empolgação em torno das propriedades ocultas/emergentes dos LLMs, no entanto, pensamos que seria mais construtivo desenvolver um benchmark que fornecesse uma variedade de tarefas de planejamento/raciocínio que pudessem servir como referência à medida que as pessoas melhorassem os LLMs por meio de ajustes finos e outras abordagens para personalizar/melhorar seu desempenho em tarefas de raciocínio. Foi isso que acabamos fazendo”, disse Kambhampati.
A equipe desenvolveu seu benchmark com base nos domínios usados na Competição Internacional de Planejamento (International Planning Competition - IPC). A estrutura consiste em várias tarefas que avaliam diferentes aspectos do raciocínio. Por exemplo, algumas tarefas avaliam a capacidade do LLM de criar planos válidos para atingir uma determinada meta, enquanto outras testam se o plano gerado é o ideal. Outros testes incluem raciocinar sobre os resultados de um plano, reconhecer se diferentes descrições de texto se referem ao mesmo objetivo, reutilizar partes de um plano em outro, embaralhar planos e muito mais.
Para realizar os testes, a equipe usou o Blocks World, um framework de problemas que gira em torno da colocação de um conjunto de diferentes blocos em uma determinada ordem. Cada problema tem uma condição inicial, um objetivo final e um conjunto de ações permitidas.
“O benchmark em si é extensível e deve ter testes de vários domínios IPC”, disse Kambhampati. “Usamos os Blocos exemplos mundiais para ilustrar as diferentes tarefas. Cada uma dessas tarefas (por exemplo, geração de planos, embaralhamento de metas etc.) também pode ser colocada em outros domínios do IPC.”
O benchmark desenvolvido por Kambhampati e seus colegas usa o Few-Shot Learning, onde o prompt dado ao modelo de aprendizado de máquina inclui um exemplo resolvido além do problema principal que deve ser resolvido.
Ao contrário de outros benchmarks, as descrições dos problemas desse novo benchmark são muito longas e detalhadas. Resolvê-los requer concentração e planejamento metódico e não pode ser enganado pelo reconhecimento de padrões. Mesmo um humano que quisesse resolvê-los teria que pensar cuidadosamente sobre cada problema, fazer anotações, possivelmente fazer visualizações e planejar a solução passo a passo.
“O raciocínio é uma tarefa do System 2 em geral. A ilusão coletiva da comunidade tem sido olhar para esses tipos de benchmarks de raciocínio que provavelmente poderiam ser tratados por meio de compilação para o System 1 (por exemplo, 'a resposta para esse dilema ético, por conclusão de padrão, é essa') em vez de realmente raciocinar sobre o que é realmente necessário para execução da tarefa em mãos”, disse Kambhampati.
Grandes modelos de linguagem são ruins em planejamento
Os pesquisadores testaram sua estrutura no Davinci, a maior versão do GPT-3. Seus experimentos mostram que o GPT-3 tem desempenho medíocre em alguns tipos de tarefas de planejamento, porém apresenta um péssimo desempenho em áreas como reutilização de planos, generalização de planos, planejamento ideal e replanejamento.
“Os estudos iniciais que vimos mostram basicamente que os LLMs são particularmente ruins em qualquer coisa que seja considerada tarefas de planejamento – incluindo geração de planos, geração de planos ideais, reutilização ou replanejamento de planos”, disse Kambhampati. “Eles se saem melhor nas tarefas relacionadas ao planejamento que não exigem cadeias de raciocínio – como embaralhar as metas.”
No futuro, os pesquisadores adicionarão casos de teste com base em outros domínios do IPC e fornecerão linhas de base de desempenho com sujeitos humanos nos mesmos benchmarks.
“Também estamos curiosos para saber se outras variantes de LLMs se saem melhor nesses benchmarks”, disse Kambhampati.
Kambhampati enfatiza que o objetivo do projeto é lançar o benchmark e dar uma ideia de onde está a linha de base atual. Os pesquisadores esperam que seu trabalho abra novas janelas para o desenvolvimento de capacidade de planejamento e raciocínio para os atuais sistemas de IA. Por exemplo, uma direção que eles propõem é avaliar a eficácia do ajuste fino de LLMs para raciocínio e planejamento em domínios específicos. A equipe já tem resultados preliminares em uma variante do GPT-3 que segue instruções que parece ter um desempenho marginalmente melhor nas tarefas fáceis, embora também permaneça em torno do nível de 5% para tarefas reais de geração de planos, disse Kambhampati.
Kambhampati também acredita que aprender e adquirir modelos de mundo seria um passo essencial para qualquer sistema de IA que possa raciocinar e planejar. Outros cientistas, incluindo o Deep Learning Pioneer Yann LeCun, fizeram sugestões semelhantes.
“Se concordarmos que o raciocínio faz parte da inteligência e pretendermos afirmar que os LLMs atingem esse patamar, certamente precisaremos de benchmarks de geração de planos para validar essa tese”, disse Kambhampati. “Ao invés de assumir uma posição negativa magistral, estamos fornecendo um benchmark, para que as pessoas que acreditam que o raciocínio pode emergir de LLMs, mesmo sem quaisquer mecanismos especiais, como modelos de mundo e raciocínio sobre dinâmica, possam usar o benchmark para apoiar seu ponto de vista."
Este artigo foi originalmente publicado por Ben Dickson (Twitter @bendee983) no TechTalks, uma publicação que examina as tendências em tecnologia, como elas afetam a maneira como vivemos e fazemos negócios e os problemas que elas resolvem. Mas também discutimos o lado maligno da tecnologia, as implicações mais sombrias da nova tecnologia e o que precisamos observar. Leia o artigo original aqui.
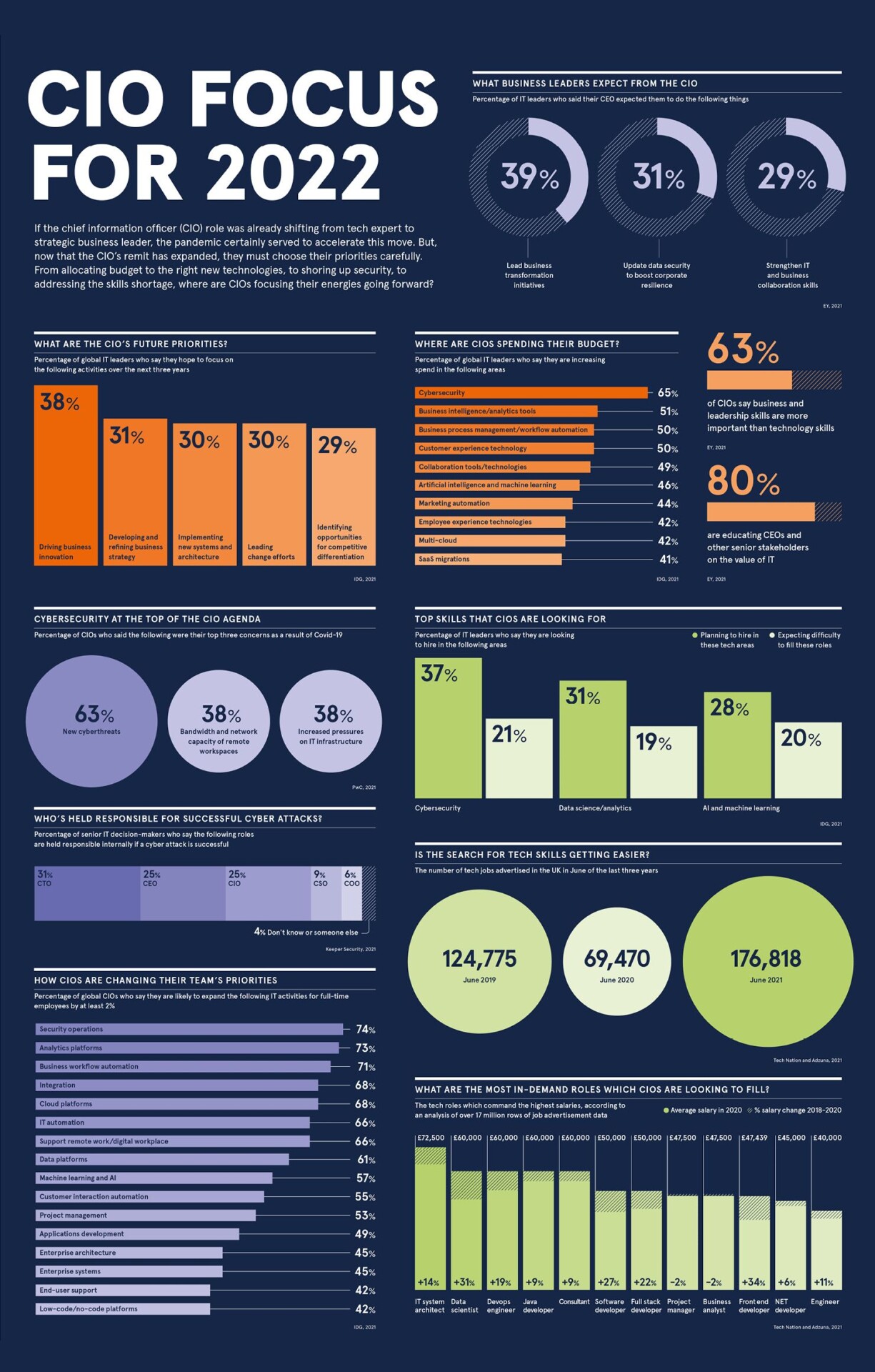
Se o cargo de Chief Information Officer já vinha evoluindo de Especialista em Tecnologia para Líder Estratégico de Negócios no decorrer dos últimos anos, a pandemia certamente serviu para acelerar esse movimento.
Porém, agora que os horizontes do CIO se expandiram, eles devem escolher suas prioridades com cuidado.
... da decisão sobre planejamento e alocação do orçamento às novas tecnologias certas, passando pelas medidas de reforço da segurança indo até o gerenciamento da atual escassez de habilidades...
Sempre devemos nos lembrar da sábias palavras do tio Ben, ou seja, "com grandes poderes vem grandes responsabilidades"...
Veja como a Raconteur entende onde os CIOs estarão concentrando suas energias daqui para frente:
A convergência do blockchain com a Inteligência Artificial gera ainda mais valor aos negócios
Resumidamente, o Blockchain é um registro de informações compartilhado e imutável que fornece uma troca imediata, compartilhada e transparente de dados criptografados para as partes envolvidas, à medida que iniciam e concluem suas transações.
Uma rede blockchain pode rastrear pedidos, pagamentos, contas, resultados da produção etc. Como os membros autorizados nessa rede compartilham uma visão única da informação, as partes ficam mais confiantes em realizar suas transações com os demais participantes do blockchain.
Também em poucas palavras, a Inteligência Artificial (IA ou AI), por sua vez, aproveita computadores e dados para imitar os recursos de resolução de problemas e tomada de decisão da mente humana. Abrangendo ainda os subcampos de aprendizado de máquina e aprendizado profundo, que usam algoritmos de IA treinados em dados para fazer previsões ou classificações e ficar mais inteligentes ao longo do tempo. Os benefícios da IA incluem automação de tarefas repetitivas, tomada de decisão aprimorada e uma melhor experiência do usuário.
Valores combinados do Blockchain e da Inteligência Artificial
Autenticidade e Segurança
O registro digital do Blockchain oferece informações sobre a estrutura por trás da IA e a proveniência dos dados que está usando, abordando o desafio da IAExplicável (Explainable AI ou xAI). Isso ajuda a melhorar a confiança na integridade dos dados e, por extensão, nas recomendações que a IA oferece.
O uso de blockchain para armazenar modelos, dados e pesos de IA, de forma definitiva e imutável (cryto Write Once, Read Many - WORM), fornecendo uma trilha de auditoria. Assim, a distribuição destes artefatos em uma rede blockchain contribui de forma clara para melhorar a segurança dos dados.
Mais precisamente, o emparelhamento do Blockchain à IA ajuda a mitigar uma das grandes vulnerabilidades atuais da IA, ou seja, o famoso "Data Poisoning" ou adulteração do seu conjunto de dados de aprendizado de máquina, com inserção de exemplos específicos para geração de resultados escusos por agressores ou instituições (também chamado de “envenenamento de dados”). Além disso, o poisoning também pode ocorrer nos pesos salvos da rede neural, a fim de se realizar inferências. Risco este que, da mesma forma, pode ser mitigado gravando-se os pesos da rede neural em blockchain.
Assim, certamente, uma das maiores vantagens da camada de proteção da Inteligência Artificial baseada em blockchain seja a geração de um registro da prova de adulteração, que não apenas ajudará a identificar casos suspeitos de “envenenamento de dados” no passado, mas também contribuirá para evitar que eles aconteçam no futuro. No Blockchain, a IA tem acesso a dados que não são apenas resistentes a adulterações e seguros por design, mas vêm com um registro matemático que prova que não foram adulterados. o que viabiliza o provisionamento de ambientes mais abertos, descentralizados e até mesmo sem permissão, democratizando a IA para todos.
Abrangência e Capilaridade
A IA é capaz de ler, entender e correlacionar dados de forma rápida e abrangente a uma velocidade incrível, trazendo um novo nível de inteligência para redes de negócios baseadas em blockchain. Por outro lado, ao fornecer acesso a grandes volumes de dados de dentro e de fora da organização, o Blockchain ajuda a IA a escalar para fornecer insights mais aplicáveis, a gerenciar o uso de dados e o compartilhamento de modelos e a criar uma economia de dados confiável e transparente.
Automação Eficaz e Eficiente
IA, Automação e Blockchain podem agregar novos valores aos processos de negócios que abrangem várias partes e etapas – removendo atritos e aumentando a velocidade e a eficiência. Por exemplo, os modelos de IA incorporados em contratos inteligentes (SmartContracts) executados em um blockchain ampliam significativamente a robustez dos algoritmos.
A utilização da Inteligência Artificial (#IA) vem afetando a vida humana de diferentes formas, proporções, momentos de maturidade e velocidade há décadas. Embora a grande parte do uso da Inteligência Artificial seja aparentemente imperceptível aos usuários finais, e, em certa medida, nem cheguemos a perceber o surgimento de novos sistemas, ferramentas ou produtos baseados em IA, há níveis de profunda transformação e penetração dessa tecnologia em nossas vidas cotidianas. Em especial em áreas onde seu uso supera de longe o desempenho e a produtividade do ser humano, principalmente nas corporações, onde a disrupção tem grande impacto e visibilidade.
No ambiente corporativo, o uso da Inteligência Artificial e o subsequente suporte a algoritmos complexos que “aprendem e crescem” (Aprendizado de Máquina - #ML) vem assumindo as tarefas operacionais, repetitivas e massivas, permitido que os seres humanos se concentrem em tarefas mais complexas, que exigem criatividade, inovação, improviso e tomada de decisões estratégicas. As decisões não estratégicas, inclusive, já começam a ser tomadas por máquinas, desde que bem treinadas para isso.
De acordo com o Personnel Today[1], um dos maiores sites de RH da Inglaterra, 38% das empresas hoje estão utilizando a Inteligência Artificial no local de trabalho, e 62% planejam começar a utilizá-la em 2020.
Os chatbots, voicebots e assistentes virtuais, por exemplo, já fazem parte de nosso cotidiano pessoal e começam a integrar nosso local de trabalho. Neste caso, nos ajudando a encontrar novos empregos, a responder a perguntas frequentes ou exercendo a função de ferramentas de treinamento e/ou orientação.
Normalmente somos levados a acreditar que ferramentas e algoritmos de computação devem ser entendidos como elementos puros e naturalmente livres de preconceitos e demais fenômenos sociais inerentes aos seres humanos. Porém, os algoritmos geralmente refletem preconceitos inconscientes, presentes de forma invisível nos dados nos quais são treinados. Esses preconceitos podem afetar grupos étnicos, de gênero, etários, religiosos ou com algum tipo de deficiência física, por exemplo.
No mundo ideal, a aplicação da IA em processos corporativos, como a contratação de pessoal, deveria eliminar os preconceitos conscientes e inconscientes que temos, uns contra os outros, contribuindo bons candidatos, pertencentes a grupos minoritários, consigam bons empregos. Infelizmente, em vez disso, a adoção de soluções de IA que não tenham sido devidamente depuradas pode chegar a dobrar a incidência desse viés ou tendência inconsciente, atribuindo um peso ainda mais desproporcional a favor ou contra uma pessoa ou grupo comparado a outro.
O real impacto da adoção da IA em diversos cenários corporativos e cotidianos têm sido foco de estudo nas mais diversas esferas. Um desses grupos, formado pela Microsoft, a IBM e o Vaticano[2], acaba de postular seu manifesto sobre os princípios da IA, que, em sua ótica devem abranger justiça, confiabilidade, privacidade e segurança, inclusão e transparência, além de serem auditáveis.
Baseados nesses princípios e no intuito de mitigar a ocorrência de escolhas enviesadas, os mais recentes projetos de inovação em RH (#RHTech) têm levado em consideração as seguintes boas práticas para orientar a utilização da Inteligência Artificial, do Aprendizado de Máquina (#ML) e de Algoritmos Preditivos na área de Recursos Humano:
1) Analisar os dados qualitativamente e revisar os algoritmos criteriosamente
O primeiro passo para acoplarmos a IA a projetos de RH é o desenvolvimento de (bons) Algoritmos de Aprendizado de Máquina para o processo de contratação de pessoal. Todavia, tão ou mais importante que os algoritmos é a base de dados disponível. Diferentemente das pessoas, que enxergam os dados simplesmente como um conjunto objetivo de informações, as máquinas os entendem como verdades absolutas. Ou seja, caso não haja dados diversos o suficiente para o treinamento das máquinas, o resultado pode ficar muito distante do almejado.
A Amazon, por exemplo, descobriu que seu elogiado software de contratação de pessoas aprendeu rapidamente que candidatos masculinos tendiam a ter mais experiência do que candidatos femininos, quando se tratava do setor de tecnologia. Assim, o algoritmo começou a filtrar currículos de mulheres de forma preventiva como um atalho em decorrência desse conhecimento, pois, assim como nós, as máquinas também usam “atalhos mentais” em seu processo de aprendizagem.
Essa possível disfunção, no entanto, não é exatamente culpa dos dados, mas sim da insuficiência deles para a construção de uma série histórica necessária para contemplar todo o cenário de possibilidades que o algoritmo deve considerar. Cabe, então, à equipe humana garantir que os dados usados no aprendizado não ensinem acidentalmente padrões incorretos às máquinas.
Por outro lado, certamente a diversidade pela diversidade não é uma boa opção, pois, no limite, corre-se o risco de desvalorizar o aspecto mais importante, ou seja, a aptidão técnica do candidato. Dessa forma, as respostas aos currículos avaliados devem ser baseadas nas premissas da vaga, porém sem menosprezar a diversidade. Além disso, deve-se criar um procedimento de revisões frequentes dos dados e algoritmos a fim de que não se esteja simplesmente automatizando preconceitos humanos inconscientes.
Por fim, a melhor prática, neste caso, seria enfatizar a necessidade de melhores dados e a criação de pontos de controle contínuos no pipeline de contratação da área de recursos humanos, pois, como qualquer nova abordagem tecnológica, a Inteligência Artificial é capaz de gerar bons e maus resultados.
2) Trabalhar com equipes e empresas que favoreçam explicitamente a diversidade
Uma vez que o investimento na construção de algoritmos preditivos demanda a alocação de uma equipe de desenvolvimento altamente qualificada e de custo elevado, as empresas normalmente optam por contratar consultorias externas, com especialidade em Inteligência Artificial e Machine Learning.
Com isso, torna-se necessário o acoplamento de mais uma camada de proteção à diversidade em projetos de RHTech, que passam a requerer a extensão do monitoramento aos resultados gerados pelo parceiro tecnológico em questão, validando se os programadores estão desenvolvendo soluções efetivamente livres de preconceitos.
Neste sentido, adicionar diversidade às equipes humanas de contratação (RH) e de desenvolvimento de algoritmos contribui para minimizarmos possíveis pontos cegos corporativos. Certamente, a adoção dessas políticas contribui sobremaneira para o favorecimento de soluções explícitas de diversidade, tanto internamente quanto com empresas terceiras.
3) Considerar uma perspectiva aumentada
Uma vez que o bom senso e o meio termo normalmente apontam para a direção mais adequada, os desenvolvedores de novas soluções de contratação têm optado por aplicar o conceito de “inteligência aumentada” em vez de “inteligência artificial”. Assim, as ferramentas devem agregar valor às equipes de RH, trabalhando conjuntamente e, não, de forma excludente.
A isenção do processo apenas será garantida se baseada em uma abordagem multidisciplinar, na qual os algoritmos de contratação são codificados de forma a ignorar informações demográficas explícitas, e seus resultados sejam continuamente analisados por uma equipe de RH humana, que observe em detalhe se todos os currículos selecionados realmente sinalizam neutralidade de escolha.
No caso da Amazon, o descompasso foi detectado pela equipe humana, ao perceber que os currículos eram predominantemente masculinos. Infelizmente para a o bem da evolução das ferramentas de IA para a área de Recursos Humanos, em vez de assumir que seus dados apresentavam viés e corrigir sua neutralidade, a Amazon descartou todo o projeto. Nesse caso, o vilão não foi o algoritmo, mas o padrão existente na base de currículos da empresa, utilizada para treinar o modelo computacional, cuja predominância de candidatos do gênero masculino refletia a quase ausência de mulheres observada na indústria de tecnologia.
Todavia, uma das tão desejadas inovações para facilitar o trabalho de gestores de pessoas, ou seja, um motor baseado em Machine Learning que receba 100 currículos e devolva os 5 melhores para a contratação, está chegando ao mercado. Um excelente exemplo da automação ao limite do processo de recrutamento e seleção é o chatbot de chamado Andy. Os recrutadores humanos agora poderão contar com essa nova ferramenta, sobrando mais tempo para atividades que explorem suas habilidades específicas, contribuindo para refinarmos o complicado processo de encontrar a equação perfeita.
Nesse cenário, as iniciativas de contratação de IA podem ajudar recrutadores e equipes de contratação a trabalhar de maneira mais estratégica em geral, aumentando as chances de uma empresa encontrar o candidato certo e não apenas o candidato típico ou subótimo.
Atualmente contamos com alguns aplicativos baseados em IA que auxiliam diversas fases do processo de busca pelo melhor candidato. O Paradox, por exemplo, usa o Olivia[3] como um assistente pessoal robótico, cuja função é a de executar o secretariado inerente ao processo - triagem de candidatos, agendamento de entrevistas, resposta a perguntas de candidatos e funcionários e integração de novas contratações –, permitindo que os profissionais de RH se concentrem na entrevista e escolha final dos candidatos. Outra interessante ferramenta para RH é o VCV, um robô-recrutador com inteligência artificial que procura candidatos; chama-os com perguntas usando o reconhecimento de voz e os convida a gravar uma entrevista em vídeo.
Já o Glider, por sua vez, é uma plataforma de recrutamento baseada em IA que se propõe a ajudar recrutadores a, literalmente, colocar seus esforços de contratação no “piloto automático” quando estiverem ocupados com outras tarefas ou fora do escritório. Finalmente, caso a demanda seja a de recomendação de cursos e treinamentos para os colaboradores já contratados, soluções como o SAP SuccessFactors, Cornerstone, Talentsoft e muitos outros fornecem recursos semelhantes para recomendar cursos com base na carreira e no desempenho de uma pessoa.
A convivência harmônica entre homem e máquina nos departamentos de RH fará com que as ferramentas melhorem os processos de contratação e os humanos aprimorem essas ferramentas, em um processo evolutivo contínuo.
Finalmente, as melhores ferramentas de RH baseadas em IA irão desempenhar um grande papel na transformação digital das áreas de gestão de pessoas e da força de trabalho; efetivamente reduzindo o viés humano, aumentando a eficiência na avaliação de candidatos, maximizando a aplicação da conformidade corporativa, aumentando a adoção de métricas e melhorando o aprendizado no local de trabalho. Benefícios esses, que as organizações começam a experimentar assim que iniciam suas jornadas de adoção da Inteligência Artificial e do Machine Learning no ambiente corporativo.
[1] Em um documento conjunto tornado público em 28/fev/2020, o papa, juntamente com a Microsoft e a IBM, expôs uma visão que delineou princípios para as tecnologias emergentes e pediu novos regulamentos. O Papa Francisco quer que o reconhecimento facial, a inteligência artificial e outras novas tecnologias poderosas sigam uma doutrina de princípios éticos e morais. https://finance.yahoo.com/news/pope-endorse-principles-ai-ethics-080413576.html
[2] Personnel Today é o principal site de RH de acesso gratuito do Reino Unido, recebendo em média 300.000 visitantes únicos por mês.
[3] www.paradox.ai/demo - Segundo a própria Olivia, ao se apresentar, ela é uma assistente baseada em IA que ajuda as equipes globais de recrutamento e RH a transformarem suas formas de trabalhar.